使用 LangGraph 来构建 SQL Agent
如何构建一个可以回答有关 SQL 数据库问题的 Agent 呢?
从高层次来看,SQL Agent 需要执行下面的步骤:
- 从数据库中获取可用的表
- 确定哪些表与问题相关
- 获取相关表的架构(schemas)
- 根据问题和架构中的信息生成查询
- 使用 LLM 仔细检查查询中是否存在常见错误
- 执行查询并返回结果
- 纠正数据库引擎发现的错误,直到查询成功
- 根据结果制定应对措施
设置
安装依赖项
pip install -U langgraph langchain_community "langchain[openai]" |
选择 LLM
from langchain_community.chat_models.tongyi import ChatTongyi |
配置数据库
需要创建一个数据库用于交互。创建一个 SQLite 数据库。SQLite 是一个轻量级数据库,易于设置和使用。我们将加载该chinook数据库,它是一个代表数字媒体商店的示例数据库。
import requests |
使用包中提供的便捷 SQL 数据库包装器langchain_community与数据库进行交互。该包装器提供了一个简单的接口来执行 SQL 查询并获取结果:
from langchain_community.utilities import SQLDatabase |
Dialect: sqlite |
数据库交互工具
langchain-community实现了一些用于与我们的交互的内置工具SQLDatabase,包括列出表、读取表模式以及检查和运行查询的工具:
from langchain_community.agent_toolkits import SQLDatabaseToolkit |
sql_db_query: Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error me |
使用 prebuilt agent
上面我们获取了需要的工具,现在我们可以通过一行代码初始化一个预建的代理。
为了定义 Agent 的行为,我们需要编写一个 System Prompt。
from langgraph.prebuilt import create_react_agent |
在这个 System Prompt 中包含许多指令,例如始终在其他工具之前或之后运行特定工具。后续可以通过图表的结构强制执行这些行为,从而提供更高程度的控制并简化提示。
运行 Agent 观察结构:
================================ Human Message ================================= |
效果很好:Agent 正确列出了表,获得了模式,编写了查询,检查了查询,并运行它以告知其最终响应。
自定义 Agent
Prebuilt Agent 可以让我们快速上手,但是每一步中 Agent 都可以去使用全部的 Tool。
在上面的案例中,我们通过设计 System Prompt来限制他的行为。
比如我们要求 Agent 始终从 “list tables” Tool 开始。
To start you should ALWAYS look at the tables in the database to see what you |
并在执行查询之前始终运行查询检查工具。
You MUST double check your query before executing it. If you get an error while |
为了解决这个问题,我们可以通过自定义 Agent 在 LangGraph 中实现更高程度的控制。
下面,我们将实现一个简单的 ReAct Agent 设置,并为特定的工具调用设置专用节点。我们将使用与 Prebuilt Agent 相同的状态。
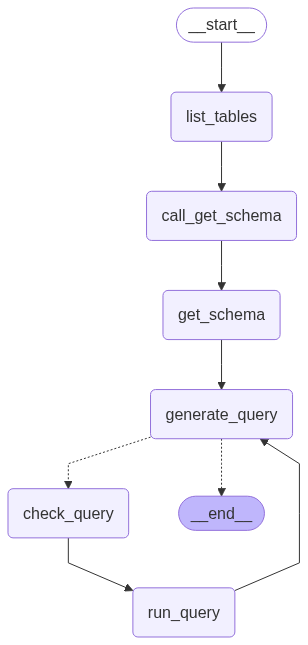
我们为以下步骤构建专用节点:
- 列出数据库表 - Listing DB tables
- 调用“获取架构”工具 - Calling the “get schema” tool
- 生成查询 - Generating a query
- 检查查询 - Checking the query
通过将这些步骤存放在专用节点,我们可以:
- 在需要的时候让 Agent 强制调用工具
- 自定义与每个步骤相关的提示
from typing import Literal |
这里会有一个小问题,
LangChain 支持的 tool_choice="any" 是为 OpenAI、Anthropic 等模型设计的。但阿里通义模型(如 Qwen)目前只接受 "none" 、 "auto"以及 object结构 ,否则会抛出 400 参数错误。
所以我去查询了通义千问的 API,结果如下:
tool_choice string 或 object (可选)
在使用tools参数时,用于控制模型调用指定工具。有三种取值:
- “none”表示不调用工具。tools参数为空时,默认值为”none”。
- “auto”表示由模型判断是否调用工具,可能调用也可能不调用。tools参数不为空时,默认值为”auto”。
- object结构可以指定模型调用的工具。例如tool_choice={“type”: “function”, “function”: {“name”: “user_function”}}。
- type只支持指定为”function”。
- function
- name表示期望被调用的工具名称,例如”get_current_time”。
下面给出配置方法:
场景1:让模型自动判断是否调用工具
llm_with_tools = llm.bind_tools([get_schema_tool], tool_choice="auto")
场景2:不调用工具
llm_with_tools = llm.bind_tools([get_schema_tool], tool_choice="none")
场景3:强制调用某个工具(如
get_schema)llm_with_tools = llm.bind_tools(
[get_schema_tool],
tool_choice={"type": "function", "function": {"name": "get_schema"}}
)
最后,我们使用 Graph API 将这些步骤组合成一个工作流。我们在查询生成步骤中定义一个条件边(conditional edge),如果生成了查询,该条件边将路由到查询检查器(query checker);如果不存在任何工具调用,则条件边将结束,这样 LLM 就已对查询作出响应。
def should_continue(state: MessagesState) -> Literal[END, "check_query"]: |
我们可以将 Graph 可视化:
from IPython.display import Image |
接下来可以像之前一样调用 Graph:
# 设置用户输入的问题 |
参考内容:
How Qwen Function Calling works?

在使用带有工具调用(tool calling)能力的语言模型时,所有带 "role": "tool" 的消息必须紧接在一条具有 "tool_calls" 字段的 assistant 消息之后,而且两者必须一一对应。
| 消息类型 | 要求 |
|---|---|
ToolMessage |
必须回应一条前面紧邻的 AIMessage,且该 AIMessage 必须有 tool_calls |
AIMessage |
如果触发了工具调用(即 tool_calls 非空),就必须接收响应 ToolMessage |
[ |